
提取、查找、替换数据的王者——REGEXP正则函数
作者:ITFANS来源:部落窝教育发布时间:2024-08-06 15:17:29点击:1079
编按:
详细介绍WPS新函数REGEXP正则函数的用法。
在《两个不用嵌套的万能提取公式》文章中我们使用了WPS的正则函数REGEXP。今天为大家详细介绍这个函数的强大功能。
1.作用与语法
REGEXP函数根据正则表达式对字符串进行提取、判断或替换。
=REGEXP(字符串,正则表达式,[匹配模式],[替换内容])
前两个参数必选,后两个参数则可以根据实际需要选用。
正则表达式:就是用一些特殊符号表达的字符串规律。譬如"[0-9]"表示任意单个数字,"[A-Z]"表示任意大写单字母。
匹配模式:有三种,0、1、2。0(默认值)表示提取,1表示判断,2表示替换。
替换内容:匹配模式为2时才需要,用于指定替换后的内容。若不指定替换内容则表示删除满足正则表达式中的字符。
2.最常用正则表达式字符集
下表简要介绍几种正则表达式中最常用的字符集及含义。
|
最常见的字符集 |
含义 |
|
[0-9] |
0到9的数字字符集 |
|
|
等效于[0-9] |
|
|
任意3位数的字符集。3可以是需要的任何正整数 |
|
[A-Z] |
A到Z的大写字母字符集 |
|
[a-z] |
a到z的小写字母字符集 |
|
[A-z] |
所有大小写字母字符集 |
|
|
0到9和A到z加下划线_的字符集 |
|
[一-龟] |
常用的汉字字符集 |
|
[一-龥] |
所有汉字字符集 |
|
[一-龟]+ |
任意汉字组成的一段连续字符集 |
|
[A-z]+ |
任意大小写字母组成的一段连续字符集 |
|
[0-9.-]+ |
任意整数与小数字符集 |
|
[A-z].+ |
以字母开头的所有字符集 |
|
[一-龟].+ |
以汉字开头的所有字符集 |
|
[^0-9] |
非数字字符集 |
|
|
等效于[^0-9] |
|
[^A-z] |
非字母字符集 |
|
[^一-龟] |
非中文字符集 |
|
|
非数字和字母、下划线_的字符集 |
2. REGEXP基本用法
1)提取模式
提取模式只需使用前两个参数。
譬如提取第一个汉字前的所有内容:
=REGEXP(A2,"^[^一-龟]+")
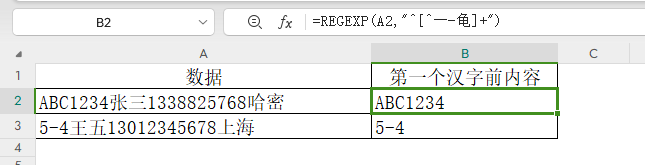
说明:
第一个^,表示从字符串的开头进行匹配;方括号中的^表示排除,[^一-龟]代表非中文字符,[^一-龟]+表示至少1个字符长的非中文字符。
再如提取第一个汉字起的所有内容:
=REGEXP(A2,"[一-龟].+")
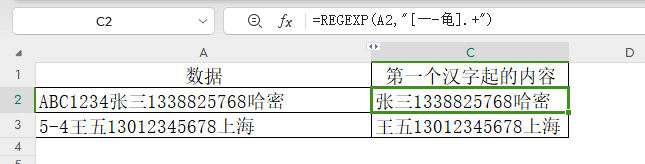
2)判断模式
第三参数为1就是判断模式。
譬如判断下方型号是否以AB字母开头的:
=REGEXP(A7,"^AB.",1)
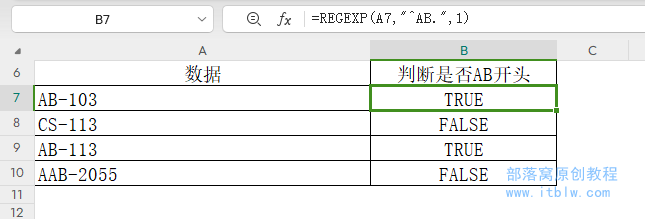
说明:
.(小圆点),表示任意字符(换行符除外);AB.,表示以AB开头的任意字符。
3)替换模式
第三参数是2,则进行替换操作。
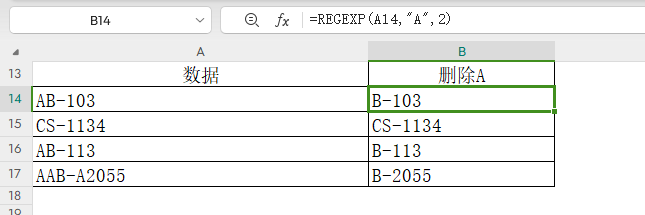
譬如将数据中所有A替换为H。
公式:=REGEXP(A14,"A",2,"H")
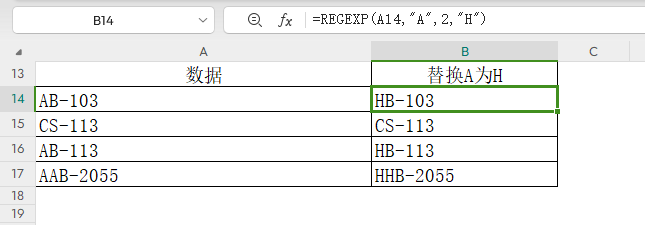
替换模式下,若第四参数为空,则表示删除相应字符。
3.典型运用
1)按号段提取手机号
譬如提取属于移动的手机号。
=IFERROR(REGEXP(A2,"(?<=^|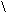 D)(134|135|136|137|138|139|147|150|151|152|157|158|159|187|188|195|197|198)d{8}(?=D|$)"),"非移动或号码错误")
D)(134|135|136|137|138|139|147|150|151|152|157|158|159|187|188|195|197|198)d{8}(?=D|$)"),"非移动或号码错误")
说明:
(134|135|136|137|138|139|147|150|151|152|157|158|159|187|188|195|197|198) ,是一个分组, “|”是或逻辑符,用于匹配多个可能的号段。
d{8},d是数字字符集,{8}表示前面的字符出现8次,也就是号段后出现8位数字。
以上两段用于提取符合号段的11位数字。
(?<=^|D)表示从字符串开头或者第一个非数字字符后开始提取。(?<=…),表示某某后的一个位置;D等效于[^0-9]。
(?=D|$),表示提取的手机号位于一个非数字或字符串末尾之前。(?=…),表示某某前的一个位置;$,表示字符串结尾。
添加(?<=^|D)和(?=D|$)定位提取位置,确保只能从11位数字中提取手机号码。因此表中两串超过11位的红色号码都判定为错误。
另外,上面的号码段分组可以用字符集来简化。
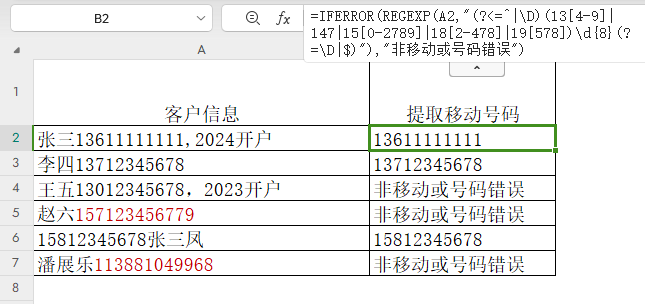
=IFERROR(REGEXP(A2,"(?<=^|D)(13[4-9]|147|15[0-2789]|18[2-478]|19[578])d{8}(?=D|$)"),"非移动或号码错误")
2)交换数据位置
用括号将数据分组,然后在替换模式下交换数据位置。交换中可增加或删除内容。
譬如将“001-原封机10G”改成“原封机(旧款)001-10G”。
=REGEXP(A2,"(d{3,4}-)([一-龟]+)",2,"2(旧款)1")
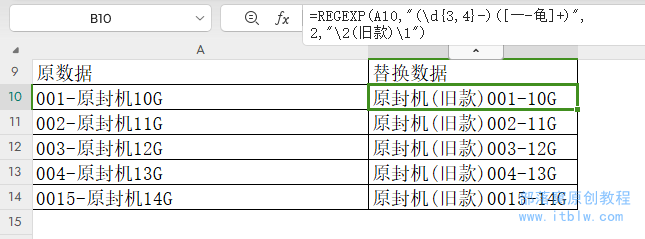
说明:
(d{3,4}-),表示将3位或4位数字加上“-”符号作为分组1。
([一-龟]+),表示将任意字数的汉字作为分组2。
2(旧款)1,表示将分组2加上字符“(旧款)”并放在分组1之前,从而实现了数据位置的交换。
3)文本中的数字运算
可以用REGEXP提取出所有数字,然后进行运算。
比如下表是产品长、宽、高数值,现在需要计算体积。
=PRODUCT(--REGEXP(A18,"[d.]+"))
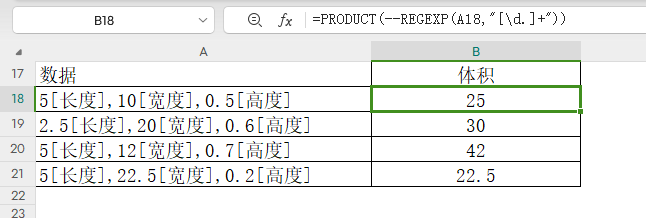
说明:
[d.]+,表示所有正整数与小数。
4)复杂数据分列
下表需要将系统导出数据分成4列,但可用的分隔符只有一个逗号。
=REGEXP(A2,{"d{3}","[一-龟]+","d{11}","(?<=,)d{4}"})
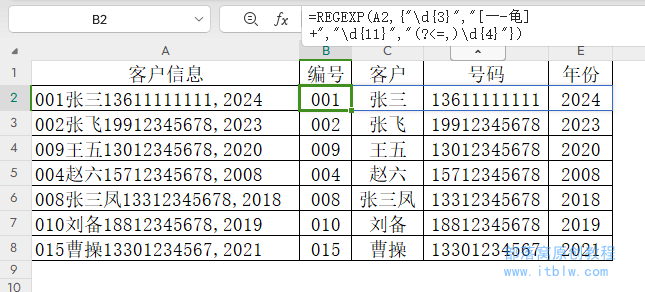
说明:
REGEXP函数的第二参数支持数组,此处用数组分别提取实现了分列。
d{3},表示提取3位数字。此处满足3位数字提取的有多个,但在数组下,只会返回第一个结果,就是最前面的编号。
(?<=,)d{4},表示从逗号后提取4位数字。
5)多分隔符提取数据
直接用非分隔符字符集进行提取。
=REGEXP(A12,"[^, /、]+")
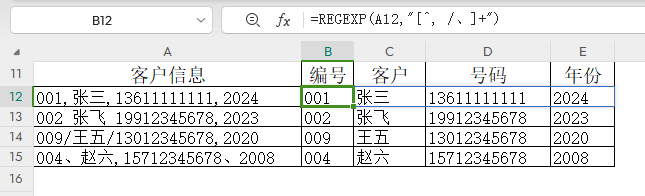
说明:
数据中的分隔符包括英文逗号、空格、斜杠、顿号。[^, /、]+,可以得到除分隔符外的任意字符组合。
如果大家对正则表达式的学习有兴趣,请留言,若需要的同学较多,我们将安排出教程。
本文配套的练习课件请添加客服微信buluowojiaoyu索取。
做Excel高手,快速提升工作效率,部落窝教育Excel精品好课任你选择!
扫下方二维码关注公众号,可随时随地学习Excel:

相关推荐:
版权申明:
本文作者ITFANS;部落窝教育享有稿件专有使用权。若需转载请联系部落窝教育。